Quantization: Optimizing GPU Requirements for Pre-training Models
In the realm of artificial intelligence and machine learning, the quest for efficiency is perpetual. As models grow larger and more complex, the computational resources required to train and deploy them skyrocket. However, a promising technique called quantization offers a beacon of hope in this landscape, particularly concerning the pre-training phase of models.
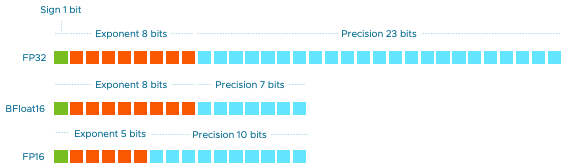
Quantization, at its core, is a process of transforming high-precision numerical representations into lower precision formats. Statistically projecting the original 32-bit floating-point numbers into lower precision spaces using scaling factors derived from the range of the original floats, quantization unlocks significant savings in memory and computational resources without compromising performance.
In the context of deep learning, where neural networks often comprise millions or even billions of parameters, this reduction in precision holds immense promise for optimizing memory usage and computational efficiency. By quantizing parameters into lower precision representations, such as integers or fixed-point numbers, deep learning models can operate with reduced memory footprint and faster computation, making them more accessible for deployment on a diverse range of hardware platforms.
Crucially, modern deep learning frameworks and libraries have embraced the paradigm of quantization-aware training (QAT). This approach integrates quantization directly into the training process, enabling the model to learn optimal scaling factors during training. By incorporating quantization into the optimization process, models can adapt to the specific characteristics of the data and the hardware platform, resulting in more efficient and effective utilization of computational resources.
One notable precision format that has gained traction in the deep learning community is BFLOAT16 (Brain Floating Point 16-bit). BFLOAT16 strikes a delicate balance between precision and efficiency by maintaining the dynamic range of FP32 (32-bit floating point) while halving the memory footprint. This makes BFLOAT16 an attractive choice for pre-training large language models (LLMs) and other deep learning applications where memory efficiency is paramount.
In the realm of LLMs, BFLOAT16 has emerged as a preferred precision format for pre-training due to its ability to preserve model performance while significantly reducing memory requirements. Notably, models such as FLAN-T5 have been successfully pre-trained using BFLOAT16, demonstrating the viability and effectiveness of this precision format in real-world applications.
The adoption of quantization and precision formats like BFLOAT16 underscores a broader trend in the field of deep learning: the relentless pursuit of efficiency and scalability. As models continue to grow in size and complexity, the need for techniques that optimize memory usage and computational resources becomes increasingly pressing. Quantization represents a pivotal step towards democratizing access to cutting-edge deep learning models, making them deployable on a wide range of hardware platforms, from edge devices to cloud infrastructure.