How AI Models Learn from Huge Amounts of New Information — Without Being Retrained
Published On : November 3, 2025
In the world of AI, people often think that for a model to “learn” something new, it must be trained again.
But that’s not always true anymore.
Thanks to Retrieval-Augmented Generation (RAG) and vector databases, modern AI systems can access massive amounts of fresh data — and use it instantly — without any retraining process.

Let’s understand how that’s possible 👇
🏗️ Traditional Learning vs. Dynamic Learning
1. Traditional (Training-based) Learning
In classical machine learning, a model “learns” by adjusting its internal weights through a long process called training or fine-tuning.
This is how ChatGPT, Gemini, Claude, and other LLMs were originally built — by analyzing billions of text samples and patterns.
However, retraining a large model is:
- Time-consuming
- Expensive (requires high-end GPUs)
- Static (once trained, it doesn’t know what happened yesterday)
2. Dynamic Learning Through RAG (Retrieval-Augmented Generation)
RAG introduces a smarter, more flexible idea:
Instead of re-training the model, just connect it to a knowledge base that can grow and update continuously.
Here’s what happens behind the scenes:
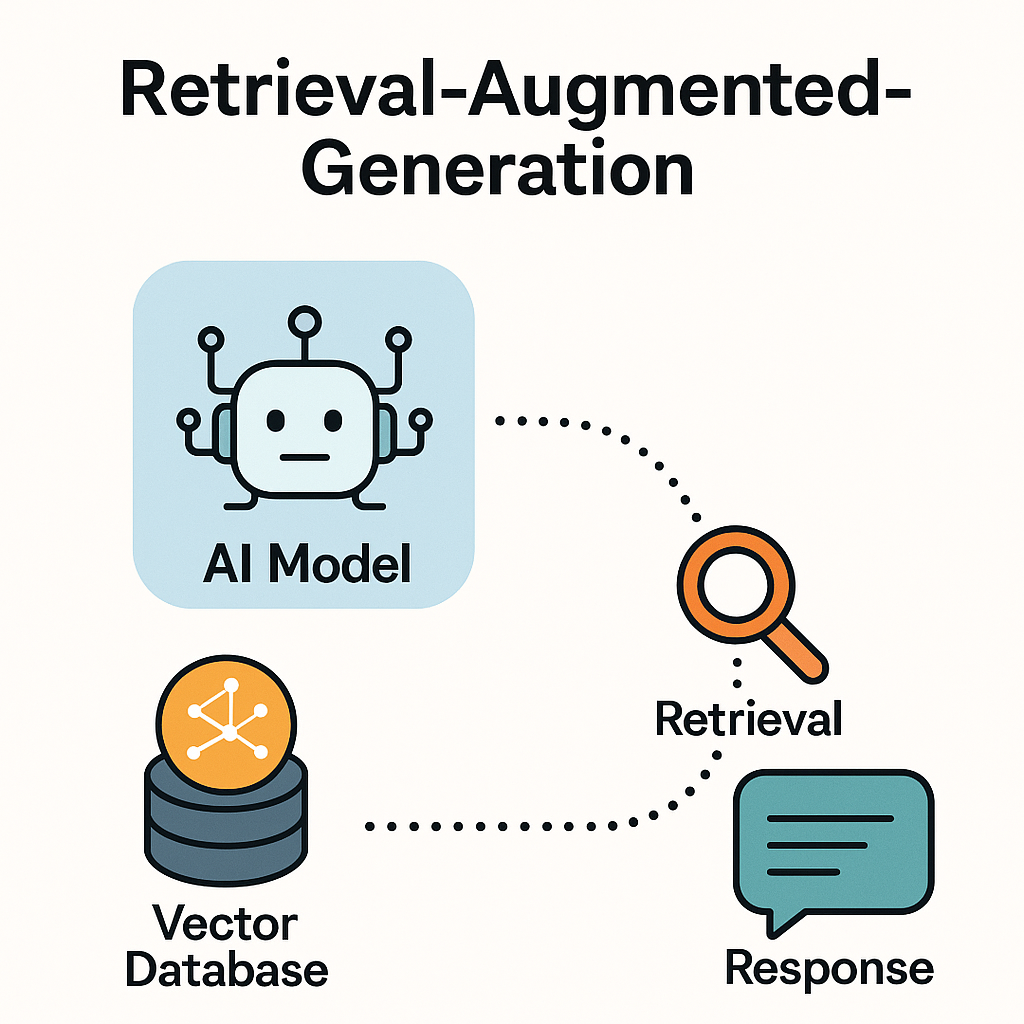
- Data Collection:
New information — such as articles, PDFs, or documents — is added to a vector database (like FAISS, Chroma, Pinecone, or Weaviate). - Vectorization:
Each document is converted into embeddings — mathematical fingerprints that represent meaning rather than words. - Fast Search:
When you ask a question, the system converts your query into an embedding and performs a similarity search in the vector DB to find the most relevant chunks of information. - Context Injection:
The retrieved data is inserted into the model’s prompt dynamically, before generating an answer. - Response Generation:
The LLM (like Mistral, LLaMA, or GPT) then reads that context and produces a meaningful, up-to-date answer — without any retraining at all.
⚡ Example: Local AI with Ollama and LangChain
Let’s say you’re using Ollama to run a local model like Mistral.
You connect it with LangChain and a vector database.
Here’s how it behaves:
- You upload thousands of new company documents.
- LangChain processes and stores them as embeddings in the vector DB.
- When you ask, “What’s our client’s 2024 project status?”, the model retrieves only the relevant documents — and answers intelligently.
Even though the model never “learned” these documents during training, it acts as if it did — because it read them at runtime.
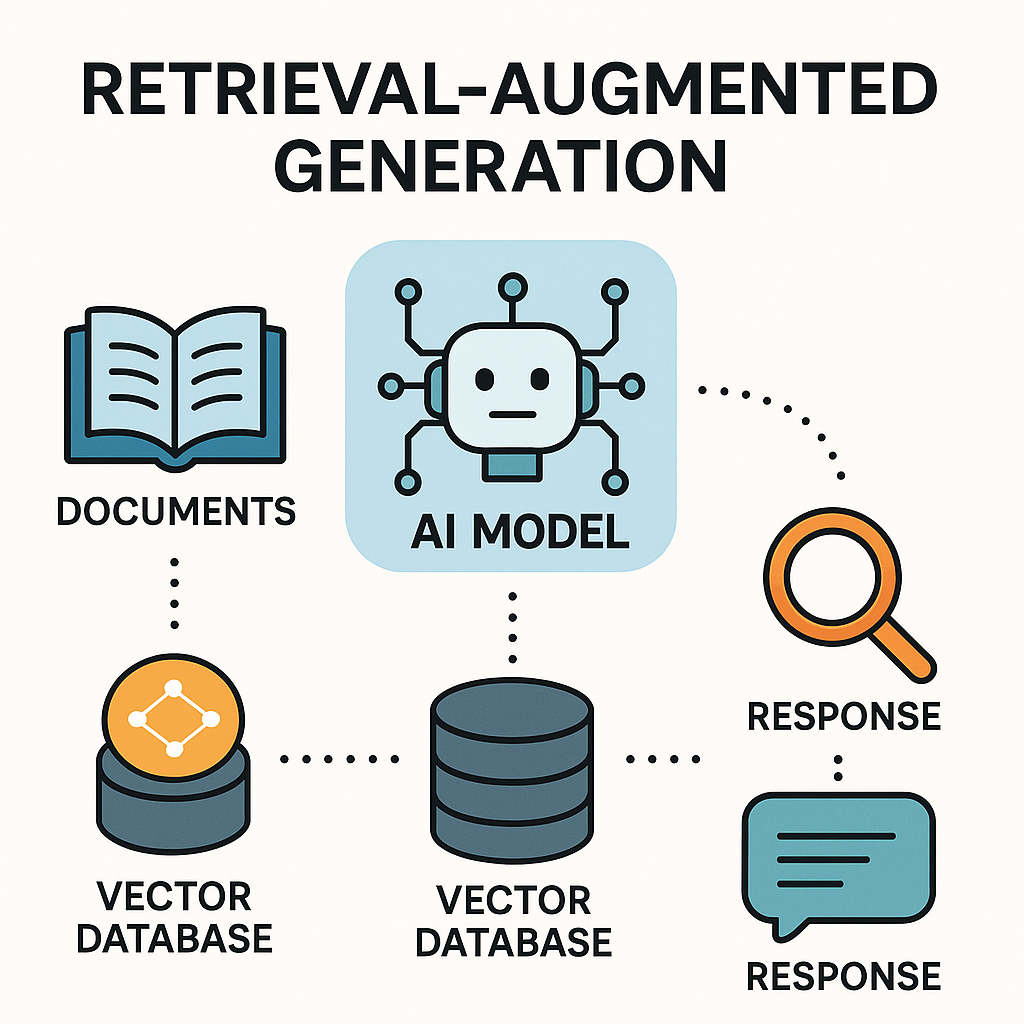
🧩 The Secret: External Memory
This system works because of a key design principle:
The LLM stays static, but the knowledge base evolves.
The vector database acts like an external brain, or memory module, that the model can “look up” whenever it needs information.
This allows AI to stay current, scalable, and adaptive — all without touching its internal parameters.
🚀 Benefits of Learning Without Retraining
✅ Always Up-to-Date: Add new information anytime — the model uses it instantly.
✅ Cheaper: No need for GPU-intensive fine-tuning.
✅ Private: Your data stays in your own local vector DB (especially useful when using Ollama locally).
✅ Modular: You can swap data sources or models anytime.
🔮 The Future: Hybrid Intelligence
This approach is blurring the line between trained intelligence and retrieved intelligence.
In the near future, we’ll see systems where:
- LLMs provide reasoning and language skills
- Vector databases provide live, evolving knowledge
- Lightweight adapters (LoRA, delta tuning) add personalization
Together, they’ll create AI systems that continuously learn — without ever retraining.
🧩 Final Thought
When people say “AI learns from new data”, what they really mean is:
It doesn’t retrain — it remembers, retrieves, and reasons.
That’s how modern AI systems can stay smart, current, and useful in real-time — all thanks to RAG, vector search, and intelligent orchestration tools like LangChain.