Journeying through Real-Time Data Rivers: Understanding Apache Kafka
Published On : May 16, 2024
In the digital era, where data reigns supreme, real-time processing of information has become indispensable across various industries. Apache Kafka emerges as a stalwart in this realm, offering a robust platform for handling high-throughput, fault-tolerant messaging systems. Let’s delve into the world of Apache Kafka, deciphering its architecture, components, and its paramount role in real-time applications.
Understanding Apache Kafka:
Apache Kafka is an open-source distributed event streaming platform initially developed by LinkedIn and later donated to the Apache Software Foundation. It is designed to handle real-time data streams efficiently and reliably, making it a go-to choice for building scalable and fault-tolerant systems.
Architecture: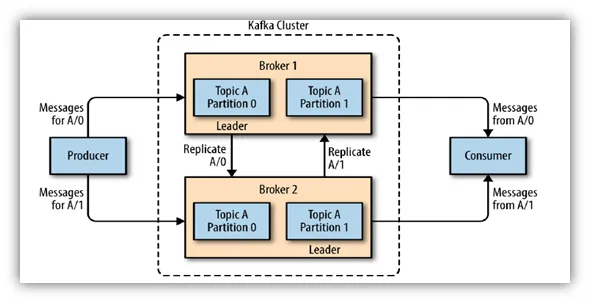
1. Broker: At the core of Kafka’s architecture are brokers. These are servers responsible for handling the storage and transmission of data. Brokers are usually deployed in a cluster to provide fault tolerance and scalability.
2. Topic: Data in Kafka is organized into topics, which are essentially feeds of messages. Topics are partitioned and replicated across brokers for high availability and parallelism.
3. Producer: Producers are entities responsible for publishing data to Kafka topics. They can push records into specific topics, which are then distributed across the Kafka cluster.
4. Consumer: Consumers subscribe to Kafka topics to retrieve data. They can consume messages in real-time as they arrive or rewind to consume historical data, depending on their requirements.
5. ZooKeeper: While not a part of Kafka itself, ZooKeeper is used for managing and coordinating Kafka brokers. It helps in maintaining metadata about Kafka clusters and ensuring distributed synchronization.
Components:
1. Connect: Apache Kafka Connect is a framework for connecting Kafka with external systems such as databases, messaging systems, or IoT devices. It facilitates seamless integration and enables building scalable, fault-tolerant data pipelines.
2. Streams: Kafka Streams is a client library for building real-time stream processing applications. It allows developers to process data directly within Kafka, enabling various use cases like real-time analytics, event-driven architectures, and more.
Real-Time Applications:
Apache Kafka finds applications across a wide spectrum of industries and use cases:
1. Messaging Systems: Kafka serves as a high-performance replacement for traditional message brokers, enabling efficient communication between microservices and applications.
2. Log Aggregation: It’s commonly used for collecting and aggregating log data from various sources, providing a centralized platform for real-time monitoring and analysis.
3. Real-Time Analytics: Kafka’s ability to handle high-throughput, real-time data streams makes it ideal for building analytics platforms that require processing large volumes of data with low latency.
4. Internet of Things (IoT): In IoT ecosystems, Kafka acts as a backbone for ingesting and processing sensor data in real-time, enabling real-time monitoring, analysis, and decision-making.
Why Apache Kafka?
1. Scalability: Kafka’s distributed architecture allows it to scale seamlessly by adding more brokers to the cluster, making it suitable for handling large volumes of data.
2. Fault Tolerance: With built-in replication and partitioning, Kafka ensures high availability and fault tolerance, minimizing data loss and ensuring data integrity.
3. Real-Time Processing: Its ability to process and deliver messages in real-time makes Kafka indispensable for applications that require low latency and high throughput.
4. Ecosystem Integration: Kafka’s extensive ecosystem, including connectors, libraries, and tools, makes it easy to integrate with existing systems and build end-to-end solutions.
Lets understand with Real-World Example: E-commerce Platform
Consider a large e-commerce platform that caters to millions of customers worldwide. This platform generates a vast amount of data every second, including user interactions, product updates, inventory changes, and transaction records. To provide a seamless shopping experience and gain valuable insights, the platform needs to process this data in real-time.
Here’s how Apache Kafka can be leveraged in this scenario:
- Real-Time Order Processing: When a customer places an order on the e-commerce platform, the order details need to be processed in real-time to update inventory, trigger shipping, and send order confirmations. Apache Kafka can be used to publish order events to a dedicated Kafka topic. Producers within the platform’s backend services push order data to Kafka topics, ensuring that order information is processed immediately.
- Inventory Management: Inventory updates are critical for ensuring product availability and preventing overselling. Kafka can be used to stream inventory changes from various sources, such as warehouses, suppliers, and online stores, into a centralized Kafka topic. This enables real-time synchronization of inventory data across the platform, ensuring that product availability is accurately reflected to customers.
- Fraud Detection and Prevention: Real-time fraud detection is essential for protecting the e-commerce platform and its customers from fraudulent activities. By streaming transaction data, user interactions, and behavioral patterns into Kafka topics, the platform can employ real-time analytics and machine learning models to detect suspicious activities, such as unusual purchase behavior or payment anomalies, and take immediate action to mitigate risks.
- Personalized Recommendations: Providing personalized product recommendations enhances the shopping experience and increases customer engagement. Apache Kafka can be used to capture user interactions, browsing history, and purchase patterns in real-time. By processing this data stream with Kafka Streams, the platform can generate personalized recommendations for each user in real-time, improving conversion rates and customer satisfaction.
- Monitoring and Analytics: Monitoring the health and performance of the e-commerce platform is crucial for identifying issues and optimizing performance. Kafka can serve as a central logging and monitoring platform by aggregating logs, metrics, and events from various components of the system. Real-time analytics tools can then analyze this data stream to detect anomalies, track key performance indicators, and trigger alerts for proactive maintenance and troubleshooting.
Apache Kafka emerges as a powerful tool for unlocking the potential of real-time data streams. With its scalable architecture, fault-tolerant design, and seamless integration capabilities, Kafka empowers organizations to build robust, real-time applications across various domains, driving innovation and efficiency in the digital age.