Unlocking Future Knowledge: The Evolution of NLP with Retrieval-Augmented Generation (RAG)
Published On : April 29, 2024
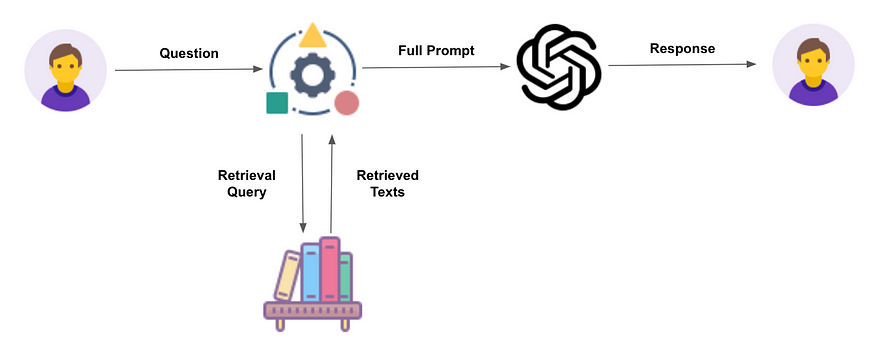
In the dynamic realm of natural language processing (NLP), the quest for models capable of accessing and integrating future knowledge has long been a central challenge. Traditional approaches often falter when confronted with new information not available during model training, hampering adaptability and accuracy. This article explores how the Retrieval-Augmented Generation (RAG) framework addresses this fundamental issue, revolutionizing the landscape of NLP.
Understanding RAG:
A Framework for Dynamic Knowledge Integration
Retrieval-Augmented Generation (RAG) stands as a transformative framework within NLP, offering a solution to the challenge of accessing future knowledge. At its core, RAG enables models to dynamically retrieve and incorporate external knowledge sources at inference time, providing access to up-to-date information. This section delves into the two-step process of retrieval and generation that defines the RAG framework, highlighting its ability to empower models with real-time adaptability.
The Retrieval Step:
Accessing Up-to-Date Knowledge
Central to the RAG framework is the retrieval step, where models scour vast knowledge sources to find relevant information related to the input prompt. Leveraging retrieval mechanisms, RAG-equipped models can access up-to-date knowledge from databases, documents, or the internet, even if it wasn’t available during training. This section explores how the retrieval step enables models to bridge the gap between existing knowledge and future information, laying the groundwork for dynamic adaptation.
The Generation Step:
Integrating External Context
Once relevant information is retrieved, RAG employs it to enhance the generation process, producing coherent and contextually rich responses. By integrating retrieved knowledge into the generation step, RAG-equipped models can generate more informed and accurate outputs, even in novel or evolving scenarios. This section elucidates how the integration of external context elevates the performance and robustness of NLP systems, unlocking new possibilities for real-time adaptation.
Connecting Diverse Data Sources: Expanding RAG’s Knowledge Access
One of the key strengths of the Retrieval-Augmented Generation (RAG) framework lies in its ability to connect with diverse data sources, enriching the model’s knowledge base and enhancing its contextual understanding. While RAG can leverage various types of data repositories, including text corpora and structured databases, the integration of vector databases offers unique advantages.
Text Corpora and Documents:
Traditional text corpora and document repositories serve as rich sources of linguistic context and domain-specific knowledge. By accessing vast collections of written text, RAG can retrieve relevant passages and augment its understanding of language patterns and semantics.
Structured Databases:
Structured databases, such as relational databases or knowledge graphs, contain organized and structured data that can provide valuable contextual information. RAG can query these databases to retrieve structured facts, entities, or relationships, enriching its knowledge base with structured data.
Vector Databases:
Vector databases, also known as vector stores or vector databases, represent a specialized type of data repository optimized for storing and querying high-dimensional vectors. These databases are well-suited for representing embeddings or vector representations of documents, entities, or concepts. By connecting to vector databases, RAG can access vector representations of knowledge items, enabling efficient similarity search and retrieval.
Example Applications of Vector Databases with RAG:
- Document Embeddings: Storing document embeddings in a vector database allows RAG to retrieve semantically similar documents based on their vector representations.
- Entity Embeddings: Vector databases can store embeddings of entities, such as people, locations, or organizations, enabling RAG to retrieve relevant entity information in context-aware generation tasks.
- Concept Embeddings: RAG can leverage vector databases to store embeddings of concepts or topics, facilitating the retrieval of related concepts and enhancing the model’s contextual understanding.
By connecting to vector databases, RAG expands its repertoire of knowledge sources, enabling access to high-dimensional vector representations of data entities and concepts. This integration enhances RAG’s ability to retrieve relevant information and generate contextually rich responses, unlocking new possibilities for dynamic knowledge integration in natural language processing tasks.
Why RAG Matters
The adoption of RAG is driven by several compelling factors:
- Contextual Understanding: By incorporating external knowledge, RAG improves its ability to understand and generate text in context, leading to more coherent and accurate outputs.
- Efficiency and Accuracy: RAG’s retrieval-based approach enhances the efficiency and accuracy of text generation by leveraging existing knowledge sources, reducing the need for manual intervention and supervision.
- Scalability: RAG is highly scalable, capable of handling large knowledge bases and adapting to diverse domains and languages. This scalability makes it well-suited for a wide range of applications and use cases.
- Continuous Learning: RAG’s ability to dynamically retrieve and incorporate new information enables continuous learning and adaptation to evolving contexts and datasets.
Applications of RAG
RAG’s versatility and effectiveness have led to its adoption across a wide range of applications, including:
- Question Answering: In question-answering tasks, RAG can retrieve relevant passages from knowledge bases or documents and generate concise and accurate responses. By incorporating external context, RAG-powered systems can provide more comprehensive answers to user queries.
- Information Summarization: RAG excels at summarizing large volumes of text by retrieving salient information from diverse sources and synthesizing it into concise summaries. This capability is invaluable in applications such as news aggregation, document summarization, and content curation.
- Conversational AI: In conversational AI systems, RAG enhances the naturalness and coherence of generated responses by leveraging external knowledge. By retrieving relevant context from knowledge sources, RAG-powered chatbots can engage in more informative and contextually rich conversations with users.
- Content Generation: RAG can assist content creators by generating text that is informed by external knowledge sources. Whether it’s writing product descriptions, generating creative narratives, or composing technical documentation, RAG can augment the writing process by providing additional context and information.
In the journey towards more intelligent and capable AI systems, RAG represents a paradigm shift, unlocking new avenues for creativity, productivity, and human-machine interaction. As researchers and practitioners continue to explore and refine the capabilities of RAG, we can expect to see even more exciting developments and applications in the years to come.